




RAG has grown into a design discipline. It’s no longer about adding external knowledge to a model. It’s about choosing the right retrieval architecture for your domain.
Each approach defines a different way to store and access knowledge: vector search for meaning, hybrid retrieval for precision, graph structures for relationships, and ontologies for semantics and rules. Together they form a set of design patterns that balance simplicity, reasoning power, and governance.
This article walks through those patterns, explaining how each works under the hood and what kind of problems it’s built to solve.
Vector RAG
Vector RAG links a language model to a vector database that retrieves information by meaning rather than keywords. It encodes both documents and queries as dense vectors in the same semantic space, enabling the model to compare concepts instead of literal words. The method is simple, scalable, and underpins most RAG systems in production.
How it works
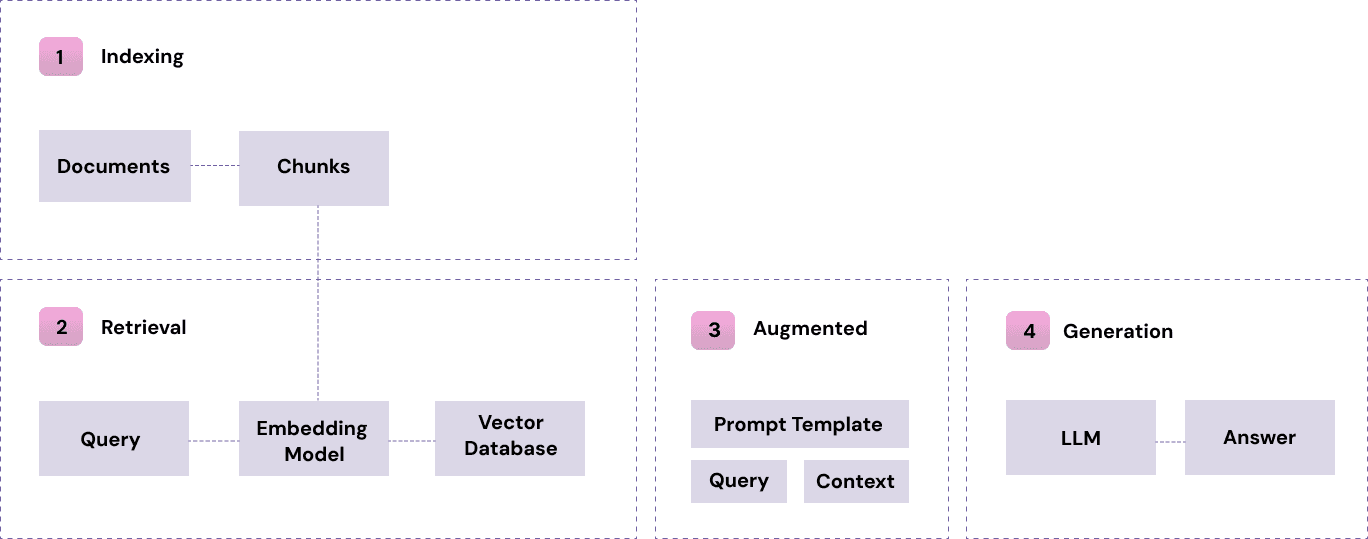
During indexing, documents are split into chunks and transformed into dense vectors through an embedding model, then stored in a vector database for fast similarity search.
At retrieval, the query is encoded in the same way and compared with stored vectors using cosine similarity (angle between vectors). The database returns the top-k most similar chunks that are appended to the user query to ground the model’s answer.
Example
Query: List our suppliers.
The retriever surfaces passages like “Vendor A delivers components,” or “Supplier C ships parts”. Even though the wording differs, the model identifies shared meaning across supplier-related text and uses those passages as grounding context.
Strengths and trade-offs
Vector RAG is fast to implement and scales easily. It excels at semantic search and factual Q&A but struggles with exact terms such as IDs or acronyms. Accuracy depends on chunking and embedding quality, and embeddings must be refreshed when data or models change.
When to use it
Ideal for documentation search, knowledge assistants, and general semantic retrieval where conceptual similarity is enough to find the right information.
Hybrid RAG
Hybrid RAG combines semantic and keyword retrieval. It pairs vector search (by meaning) with keyword search (by exact terms), improving precision on technical or structured data while preserving broad semantic recall.
How it works
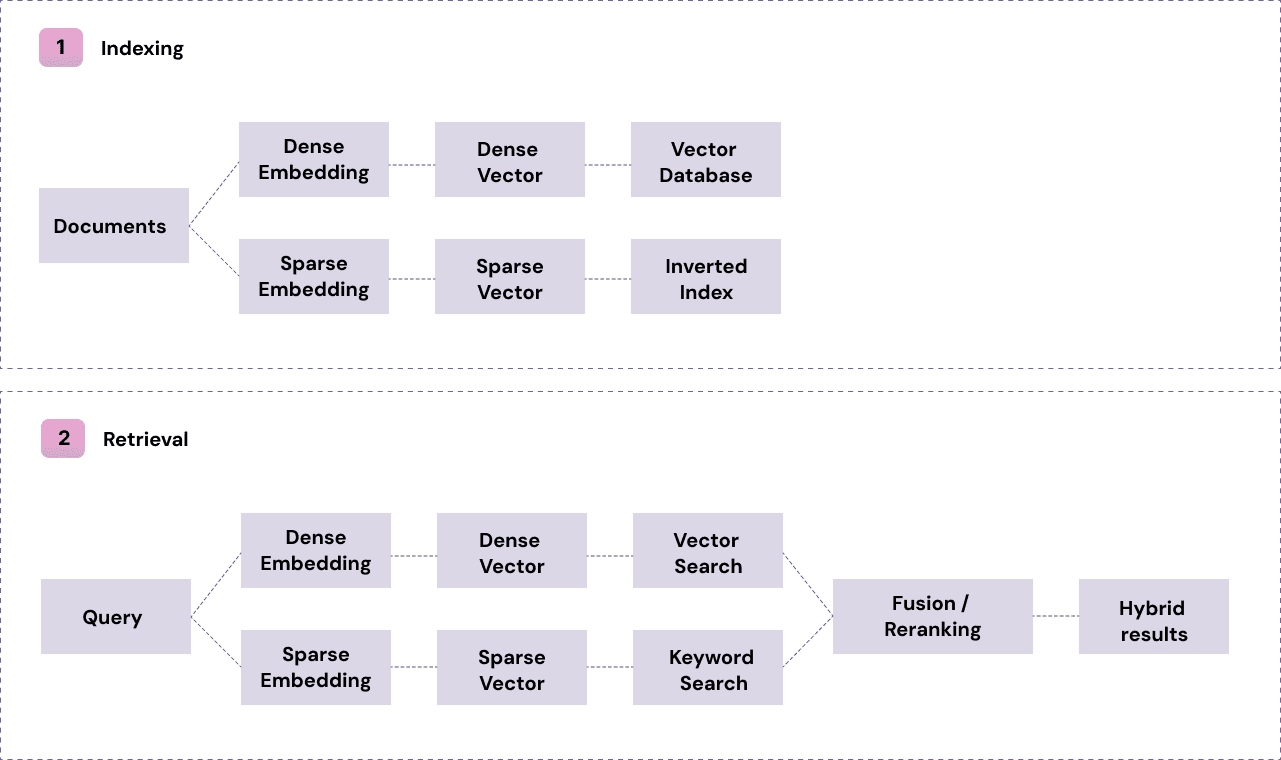
During indexing, each document is represented in two complementary ways: a dense vector that captures meaning for semantic search, and a sparse representation (inverted index or token-weight model) for exact keyword matching. Depending on the stack, these can be stored together in a hybrid index or separately as vector and inverted indexes.
At retrieval, the query follows the same dual path, semantic and lexical. Vector search finds conceptually related text, while keyword search ensures exact term matches. The two result sets are merged through fusion and reranking, balancing semantic meaning and term precision. The final ranked chunks are passed as context to the model.
Example
Query: List suppliers of Product A.
Vector search retrieves passages that mention suppliers in similar contexts, while keyword search ensures mentions of “Product A.” Fused together, they yield precise, contextually complete results.
Strengths and trade-offs
Hybrid RAG improves precision without losing recall, especially in data with mixed natural language and structured terms. It adds complexity since it has two encoders, two retrieval paths, and a fusion step but often produces more relevant answers in technical domains.
When to use it
Use Hybrid RAG when your data includes identifiers, codes, or domain-specific terms that require exact matching alongside semantic context.
Graph RAG
Graph RAG retrieves connections rather than isolated passages. Instead of comparing chunks of text, it represents information as a graph of entities and relationships. This structure allows the system to reason across links following chains like Supplier → Factory → Product to uncover how different parts of a domain relate.
How it works
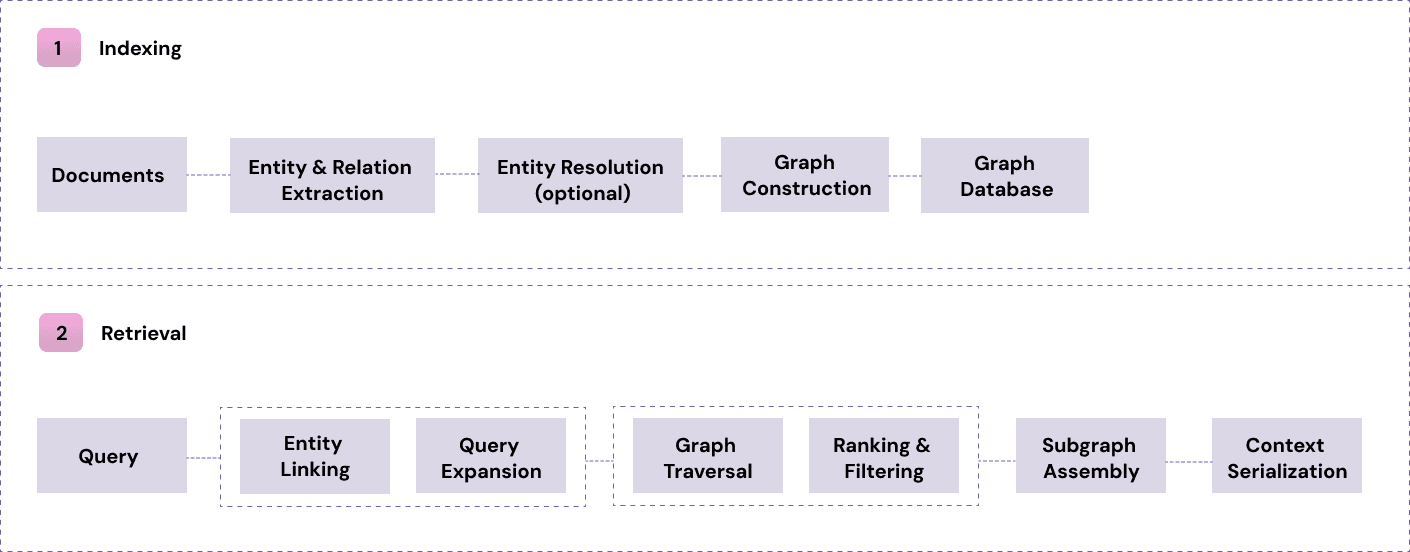
During indexing, documents are processed with entity and relation extraction. The system identifies the entities mentioned in the text (e.g., suppliers, factories, products) and the relationships between them (e.g., delivers_to, produces). These extractions are stored as triples of the form: entity → relation → entity
The result is a knowledge graph built directly from the data. It is flexible, grows organically with the corpus, and reflects whatever the extraction model finds. Optional steps like normalization or deduplication can improve quality, but the graph remains largely probabilistic because it depends on how well entities and relationships are extracted from text.
At retrieval, the system starts from the nodes that match the query and traverses connected paths to gather relevant context. It can follow multiple hops such as Supplier → Factory → Product, allowing the retriever to uncover indirect links even when no single text chunk explicitly describes them. The resulting subgraph is converted back into text and provided to the model.
Example
Query: Which suppliers could disrupt production at Plant B?
Graph RAG starts from Plant B, follows outgoing edges to the products it assembles, then follows incoming edges from suppliers feeding those products. Even if wording varies across documents, the graph captures these relationships, enabling multi-hop reasoning.
These kinds of indirect, multi-step links are typically impossible for traditional RAG approaches, which retrieve isolated passages rather than connected paths across documents. Graph RAG’s structured traversal is what makes this type of reasoning possible.
Strengths and trade-offs
Graph RAG excels at uncovering relationships and surfacing connected evidence. It supports multi-hop reasoning and provides transparent, explainable paths across documents.
The trade-offs come from its flexibility: extraction errors can accumulate, entities may be duplicated, and relationships might be incomplete. Because the graph emerges organically from text rather than being governed by a schema, there is no guaranteed global structure or predictable shape to the data.
As a result, retrieval must be exploratory at each node, the system must inspect available edges and decide which ones to follow. This iterative traversal makes Graph RAG powerful but can also make it slower and less predictable, especially as the graph grows.
When to use it
Use Graph RAG when your data naturally forms networks such as supply chains, transactions, or research citations, and when exploring relationships is as important as retrieving text.
Ontology RAG
Ontology RAG builds on graph-based retrieval but adds a formal semantic layer: an ontology that defines the allowed entity types, their properties, the relationships between them, and the rules they must satisfy. Instead of letting the graph emerge organically from text, Ontology RAG constrains how the graph is built and ensures that every piece of data fits a governed structure. This makes retrieval consistent, deterministic, and grounded in domain logic.
How it works
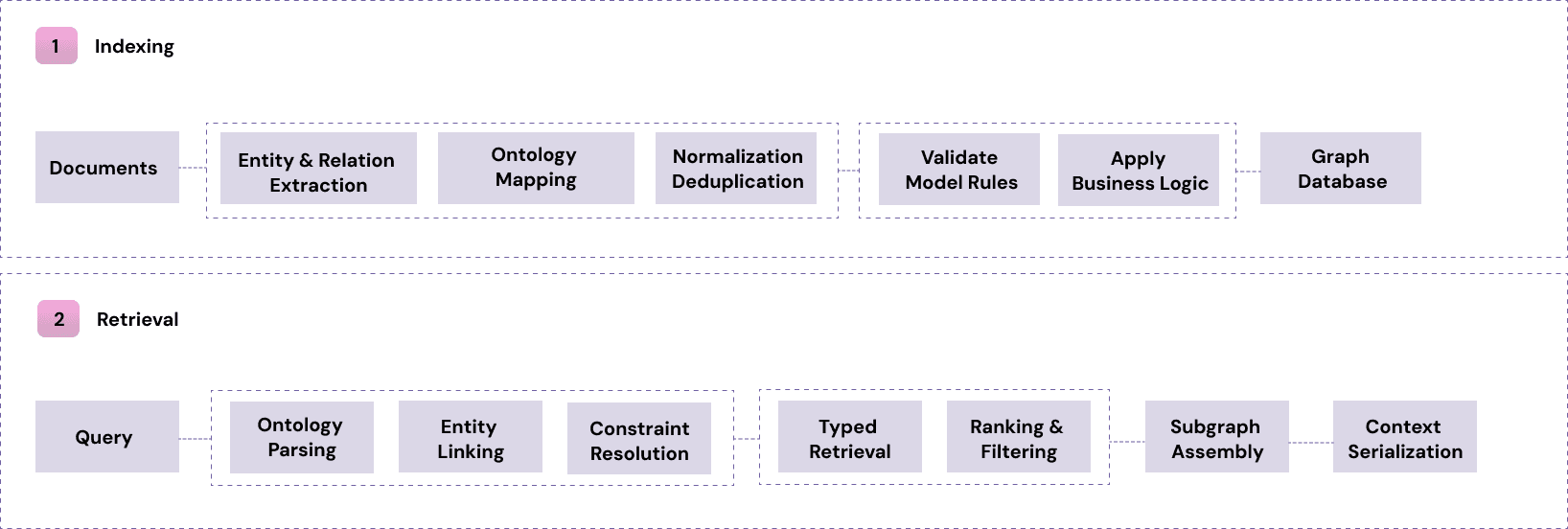
During indexing, extracted entities and relations are validated against the ontology. The ontology defines:
classes (Supplier, Factory, Product, Contract)
properties (risk_score, product_type, location)
allowed relationships (Supplier → delivers_to → Factory)
business rules (a Supplier must have a risk_score; a Factory cannot deliver directly to a Product)
Only entities that conform to the ontology are added to the graph. Others are normalized, merged, mapped into valid types, or rejected. Relationships are also checked: if a relation is not allowed by the ontology, it is not created. This produces a consistent knowledge graph whose structure is guaranteed by design.
At retrieval time, queries operate over typed entities and governed relationships.
The system first interprets the query in terms of ontology concepts—classes, properties, and constraints. If the query mentions a type (“Tier-2 supplier”), the ontology determines exactly what that class includes.
Next, the system links the query to the relevant entities in the graph and applies the ontology’s constraints. Class hierarchies allow typed retrieval: a query for “manufacturer” can match all subclasses such as “assembly plant.” Rules and properties narrow the search: for example, filtering by risk_score, status, or any required business condition.
Because every node and relationship already conforms to the ontology, the traversal is predictable: the system follows only the relationships defined in the ontology and ignores anything outside that structure. The final step assembles a subgraph that satisfies the query’s types, filters, and rules, and converts it into text for the model.
Example
Query: List all Tier-2 suppliers with a risk score above 7 contributing to Product C.
Ontology RAG first checks what qualifies as a Tier-2 supplier using the ontology’s class definitions. It then follows only the relationships defined in the ontology to find which suppliers contribute to Product C. Once that path is established, it applies the risk-score rule and returns only suppliers that meet the threshold.
Because the ontology constrains which entities can exist and how they connect, the result set is complete, consistent, and explainable.
Strengths and trade-offs
Ontology RAG brings structure and logic directly into retrieval. Instead of relying on what the model noticed in the text, it retrieves information that fits a well-defined schema and follows explicit business rules. This makes the system predictable, explainable, and aligned with how the domain actually works.
The trade-off is the upfront effort: the ontology must be designed, maintained, and agreed upon, and data must be shaped to fit it. Once that investment is made, the retrieval becomes far more reliable for domains where correctness matters.
When to use it
Ontology RAG is the right choice when the domain has strict definitions and rules such as risk scoring, manufacturing processes, contractual obligations, regulatory categories. If correctness, consistency, and explainability matter more than raw recall, the structure and constraints provided by an ontology become an advantage rather than overhead.
Advanced Retrieval Extensions
The four core RAG methods describe how knowledge is stored and retrieved. They define the architecture of retrieval itself: whether information is kept as vectors, text–keyword pairs, connected entities, or structured ontologies.
In practice, most modern systems combine these foundations with extra layers that change how retrieval behaves to be more adaptive, multimodal, or personalized.
Agentic RAG
Coordinates several retrieval steps through autonomous agents. Instead of one question and one answer, the agent breaks down a problem, asks follow-up questions, and combines the results.
Metadata-Filtered RAG
Adds structured filters like document type, region, or date range on top of vector or hybrid search. It improves precision by narrowing the search scope while keeping the same retrieval logic.
Long-Context RAG
Handles long documents such as reports or manuals by using hierarchical chunking or memory windows. It helps the model process larger contexts without changing the core retrieval method.
Multimodal RAG
Extends retrieval beyond text. Images, diagrams, and audio are embedded in the same vector space, so a query like “find diagrams about the assembly line” can retrieve both text and visuals.
Memory RAG
Keeps a short or long-term memory of previous interactions. It allows the system to recall past queries or user preferences and respond in a more context-aware way.
Conclusion
RAG is no longer a single pattern. It has expanded to cover a wide range of retrieval needs, from simple semantic lookup to systems that reason over structure, dependencies, and rules. The “best” RAG system is always the one matched to the domain: some problems only need a fast vector store, while others call for a structured representation of the domain so retrieval aligns with how the organization thinks and works.
At Blue Morpho, we focus on these highly structured domains. Teams in finance, legal, supply chain, and other enterprise contexts that need retrieval that follows their definitions, constraints, and business logic.




